
This is an honest introduction to Meilisearch, the hottest new search engine offering power and speed in a simple package.
What Is Meilisearch?
Meilisearch is a new open-source search engine built for speed and simplicity. Meilisearch offers a RESTful API, a prebuilt Docker image for easy deployment, and a loosely typed document structure for zero-config document storage.
Why Meilsearch?
Meilisearch has several benefits and neat features that other search engines may not offer:
- Simplicity
- Loosely Typed Documents
- Idempotent Document Management
- Fuzzy By Default
- Search Speed
- Indexing Speed
- API Key Management
Simplicity
Meilisearch's simplicity is its strongest selling point, making it very easy to get started using Meilisearch without needing to learn dozens of API endpoints or watch an entire webinar on how fuzzy search works.
Loosely Typed Documents
Documents in Meilisearch are loosely typed, meaning that an "age" field (for example) could be an integer in one document and a string in the next document. This may seem like a downside from an engineering standpoint, but it means that you do not need to worry about type errors when indexing documents.
Idempotent Document Management
Meilisearch also provides idempotent document CRUD endpoints such as [Documents.AddOrReplace](https://docs.meilisearch.com/reference/api/documents.html#add-or-replace-documents), which is extremely helpful for
- Avoiding the creation of duplicate documents
- Avoiding errors upon inserting duplicate documents
- Easily updating a document in place without worrying about whether the document already exists or not.
The document "AddOrReplace" endpoint is also extremely useful for "cleaning" index data. For example, in the case of a document with bad data, you can re-insert the document without worrying about re-indexing the entire index in a migration.
Fuzzy By Default
Tying in with the "Meilisearch is simple" concept, Meilisearch is also fuzzy by default, meaning that it will do typo correction by default, with no configuration necessary. While many other facets and features are involved in fuzzy search, typo correction is one of the biggest ones (and a must-have, in my opinion), so it's great that Meilisearch offers this must-have feature out of the box.
PS. For more information on how Fuzzy Search works, check out my free webinar on Clearing the Fuzzies on Fuzzy Search.
Search Speed
Meilisearch is lightning-quick when it comes to searching documents. This is great if you struggle with slow database searches (or have no search at all). Meilisearch's speed makes it a fantastic choice for "instant search" experiences, where the most relevant search results appear as you type.
Note: In my tests, there was little to no difference in search speed between Elasticsearch and Meilisearch. This is great news, knowing that Elasticsearch is also a hyper-fast search engine
Indexing Speed
When "ingesting" or indexing new content, I've noticed that Meilisearch's index analysis can be a bit faster than the same process in Elasticsearch. This may be due to Meilisearch's loosely typed nature, where each document can have a different structure, and each field can have whatever data type it likes.
Regardless of the cause, the data is clear: Meilisearch indexing is just plain faster than Elasticsearch indexing. (In my case, about 30% faster)
In Elasticsearch, indexing 1000 reviews takes from 6-7 seconds:
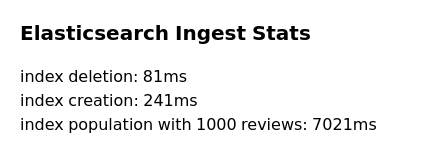
Compared to Meilisearch, indexing the same 1000 reviews takes from 4-6 seconds:

API Key Management
In addition to powerful, fast search functionality, Meilisearch offers sophisticated API key authentication at all endpoints. Developers can quickly and easily lock down Meilisearch API access and even fine-tune different API keys for different indexes - much like a database user may only have access to a single database.
This functionality comes with a caveat: There is no ability to manage API keys from the Meilisearch Admin Dashboard, so you'll have to create, view, and manage keys through the API itself... which seems to make the Admin Dashboard a bit underwhelming for "Admins.”
Meilisearch Drawbacks
Not everything is wine and roses when it comes to Meilisearch features. There are a few drawbacks you should consider before jumping in with both feet:
No Scalability
The biggest downside to Meilisearch is the lack of support for scaling Meilisearch beyond a single instance (node). Meilisearch's focus is on providing fast search results with simple implementation and integration and has not prioritized scalability. This alone makes Meilisearch a no-go for certain companies and datasets.
However, it seems some work has been done in this area in the last few months - see discussion on the GitHub Meilisearch repository.
Offline Documentation
I have seen the Meilisearch API reference documentation go offline several times while reading the documentation. This makes it challenging to learn about Meilisearch when the Meilisearch docs are down.
Multiple Identical Search Endpoints Are Confusing
While this is not a significant downside to using Meilisearch, I thought it worth mentioning. Meilisearch supports two different API methods (POST and GET) for the same Search API call. One is preferred, while the other is an optional method for better cacheability. I see this as no more than a point of potential confusion.
Conclusion
Meilisearch is a simpler alternative to Elasticsearch while offering powerful features with a lightning-quick search interface. If you want to add a new search form to your website, Meilisearch should be your first choice.



Add Your Comment